Procesamiento y Transformación de Datos en Python
 Tutor | octubre 28, 2018
Tutor | octubre 28, 2018
Seguimos trabajando en el conjunto de datos anterior (datos de la tasa de abandono de los clientes de los operadores de telecomunicaciones) para la serie Análisis de Datos en Python. Se cargan los datos usando read_csv (si ya lo hiciste no es necesario repetirlo).
import pandas as pd
import numpy as np
df = pd.read_csv('../../data/telecom_churn.csv')
df.head()
Aplicando funciones a celdas, columnas y filas
Para aplicar funciones a cada columna, use apply():
df.apply(np.max)
State WY Account length 243 Area code 510 International plan Yes Voice mail plan Yes Number vmail messages 51 Total day minutes 350.8 Total day calls 165 Total day charge 59.64 Total eve minutes 363.7 Total eve calls 170 Total eve charge 30.91 Total night minutes 395 Total night calls 175 Total night charge 17.77 Total intl minutes 20 Total intl calls 20 Total intl charge 5.4 Customer service calls 9 Churn 1 dtype: object
El método apply también se puede utilizar para aplicar una función a cada línea. Para hacer esto, especifique axis = 1. Las funciones Lambda son muy convenientes en tales escenarios. Por ejemplo, si necesitamos seleccionar todos los estados que comienzan con W, podemos hacerlo de la siguiente manera:
df[df['State'].apply(lambda state: state[0] == 'W')].head()
El método map se puede usar para reemplazar valores en una columna al pasar un diccionario de la forma {valor_viejo: valor_nuevo} como argumento:
d = {'No' : False, 'Yes' : True}
df['International plan'] = df['International plan'].map(d)
df.head()

Lo mismo se puede hacer con el método de reemplazo:
df = df.replace({'Voice mail plan': d})
df.head()
Agrupamiento de datos
En general, agrupar datos en Pandas es el siguiente:
df.groupby(by=grouping_columns)[columns_to_show].function()
El método groupby divide las grouping_columns por sus valores. Se convierten en un nuevo índice en el dataframe resultante.
Luego, se seleccionan las columnas de interés (columns_to_show). Si columns_to_show no está incluido, se incluirán todas las cláusulas no grupales.
Finalmente, una o varias funciones se aplican a los grupos obtenidos por columnas seleccionadas.
Aquí hay un ejemplo donde agrupamos los datos de acuerdo con los valores de la variable Churn y mostramos estadísticas de tres columnas en cada grupo:
columns_to_show = ['Total day minutes', 'Total eve minutes',
'Total night minutes']
df.groupby(['Churn'])[columns_to_show].describe(percentiles=[])

Hagamos lo mismo, pero de manera ligeramente diferente al pasar una lista de funciones a agg():
columns_to_show = ['Total day minutes', 'Total eve minutes',
'Total night minutes']
df.groupby(['Churn'])[columns_to_show].agg([np.mean, np.std,
np.min, np.max])
Tablas de resumen
Supongamos que deseamos ver cómo se distribuyen las observaciones en nuestra muestra en el contexto de dos variables: Churn e International Plan. Para hacerlo, podemos construir una tabla de contingencia usando el método crosstab:
pd.crosstab(df['Churn'], df['International plan'])

pd.crosstab(df['Churn'], df['Voice mail plan'], normalize=True)
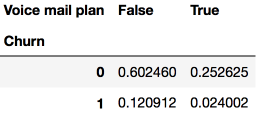
Podemos ver que la mayoría de los usuarios son leales y no utilizan servicios adicionales (plan internacional / correo de voz).
Esto se asemejará a las tablas dinámicas a aquellos familiarizados con Excel. Y, por supuesto, las tablas dinámicas se implementan en Pandas: el método pivot_table toma los siguientes parámetros:
- values – una lista de variables para calcular estadísticas para,
- index – una lista de variables para agrupar datos por,
- aggfunc – qué estadísticas necesitamos calcular para los grupos, por ejemplo, suma, media, máxima, mínima o algo más.
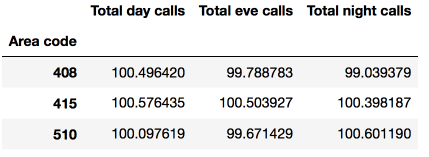
Echemos un vistazo a la cantidad promedio de llamadas de día, tarde y noche por código de área:
df.pivot_table(['Total day calls', 'Total eve calls', 'Total night calls'], ['Area code'], aggfunc='mean')
Transformaciones de DataFrame
Como muchas otras cosas en Pandas, agregar columnas a un DataFrame se puede hacer de varias maneras.
Por ejemplo, si queremos calcular el número total de llamadas para todos los usuarios, creamos la serie total_calls y la pegamos en el DataFrame:
total_calls = df['Total day calls'] + df['Total eve calls'] + \ df['Total night calls'] + df['Total intl calls'] df.insert(loc=len(df.columns), column='Total calls', value=total_calls) df.head()

Es posible agregar una columna más fácilmente sin crear una instancia de serie intermedia:
df['Total charge'] = df['Total day charge'] + df['Total eve charge'] + \
df['Total night charge'] + df['Total intl charge']
df.head()

Para eliminar columnas o filas, use el método drop, pasando los índices requeridos y el parámetro de eje (1 si elimina columnas, y nada o 0 si elimina filas). El argumento in situ indica si se debe cambiar el DataFrame original.
Con inplace = False, el método drop no cambia el DataFrame existente y devuelve uno nuevo con filas o columnas eliminadas. Con inplace = True, altera el DataFrame.
# elimina columnas df.drop(['Total charge', 'Total calls'], axis=1, inplace=True) # eliminar filas df.drop([1, 2]).head()

Written by Tutor
Related View More
Tutor | octubre 29, 2018
Clasificación de Texto con Python
Tutor | octubre 28, 2018
Predicciones simples con Python
Tutor | octubre 28, 2018
Análisis exploratorio en Python con Pandas
Tutor | octubre 28, 2018
Bibliotecas para hacer análisis de datos en Python
Tutor | octubre 28, 2018
Estructuras de Datos, Iteraciones y Condicionales en Python
Tutor | octubre 28, 2018
Análisis de Datos con Python – Una Introducción
Tutor | marzo 11, 2022
Estructura y Etiquetas en HTML5
Tutor | marzo 11, 2022
Conceptos básicos de desarrollo web
Tutor | marzo 9, 2022