Predicciones simples con Python

Seguimos trabajando en el conjunto de datos anterior (datos de la tasa de abandono de los clientes de los operadores de telecomunicaciones) para la serie Análisis de Datos en Python.
Pronosticando el abandono de clientes
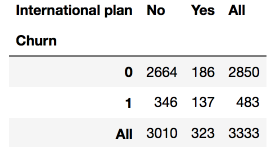
Veamos cómo se relaciona la tasa de abandono con la variable del plan internacional. Haremos esto utilizando una tabla de contingencia de tablas de referencias cruzadas y también mediante análisis visual con Seaborn (sin embargo, el análisis visual se tratará con mayor detalle en el próximo artículo).
Nota: Churn=1, significa que el cliente abandonará.
pd.crosstab(df['Churn'], df['International plan'], margins=True)
# algunos imports y comando para hacer plotting %matplotlib inline import matplotlib.pyplot as plt # pip install seaborn // Si no está instalada esa librería import seaborn as sns plt.rcParams['figure.figsize'] = (8, 6) sns.countplot(x='International plan', hue='Churn', data=df);
Vemos que, con el Plan Internacional, la tasa de abandono es mucho más alta (Churn), lo que es una observación interesante.
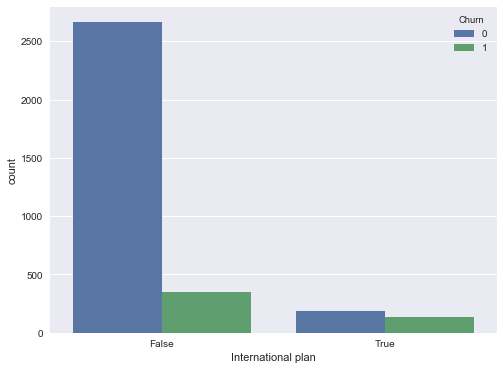
A continuación, veamos otra característica importante: las llamadas de servicio al cliente (Customer service calls). Hagamos también una tabla de resumen y una imagen.
pd.crosstab(df['Churn'], df['Customer service calls'], margins=True)
sns.countplot(x='Customer service calls', hue='Churn', data=df);
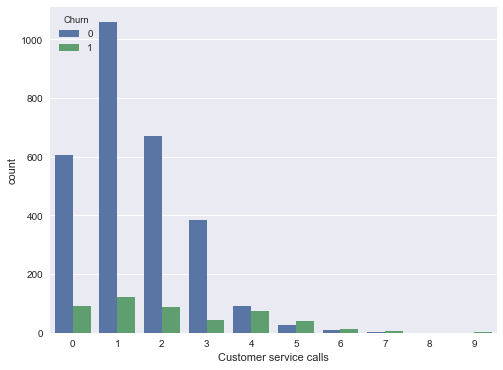
Tal vez, no sea tan obvio en la tabla de resumen, pero la imagen indica claramente que la tasa de abandono aumenta considerablemente a partir de 4 llamadas al centro de servicio.
Agreguemos ahora un atributo binario a nuestro DataFrame Customer service calls > 3. Y una vez más, veamos cómo se relaciona con el abandono o rotación.
df['Many_service_calls'] = (df['Customer service calls'] > 3).astype('int')
pd.crosstab(df['Many_service_calls'], df['Churn'], margins=True)
sns.countplot(x='Many_service_calls', hue='Churn', data=df);
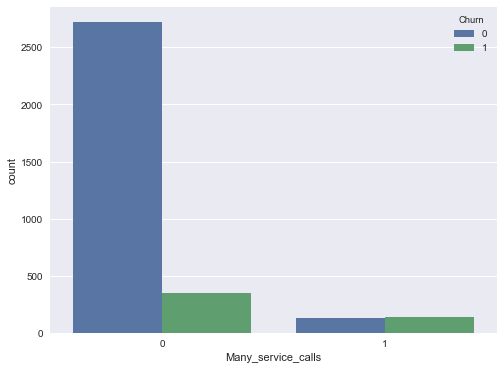
Construyamos otra tabla de contingencia que relacione a abandono (Churn) con el plan internacional y con las recientemente creadas Many_service_calls.
pd.crosstab(df['Many_service_calls'] & df['International plan'] , df['Churn'])

Por lo tanto, para pronosticar que un cliente abandonará (Churn = 1) en el caso de que el número de llamadas al centro de servicio sea mayor que 3 y se agregue el Plan Internacional, podríamos esperar una precisión de 85.8% (estamos equivocados solo 464 + 9 veces).
Este número, 85.8%, que obtuvimos con un razonamiento muy simple sirve como un buen punto de partida para los futuros modelos de aprendizaje automático que construiremos.
A medida que avanzamos en este curso, recuerde que, antes del advenimiento del aprendizaje automático, el proceso de análisis de datos se parecía a esto. Vamos a resumir lo que hemos cubierto:
La cuota de clientes leales en la muestra es del 85,5%. El modelo más ingenuo que siempre predice un “cliente leal” con dichos datos acertará en aproximadamente el 85.5% de todos los casos. Es decir, la proporción de respuestas correctas (precisión) de los modelos subsiguientes no debe ser inferior a este número y es de esperar que sea significativamente mayor.
Con la ayuda de un pronóstico simple que puede expresarse mediante la siguiente fórmula: “(Llamadas de Servicio al Cliente> 3) & (Plan internacional = Verdadero) => Churn = 1, sino Churn = 0”, podemos esperar una tasa de predicción de 85.8%, que está justo por encima del 85.5%.
Posteriormente, hablaremos sobre los árboles de decisión y descubriremos cómo encontrar dichas reglas automáticamente basándose solo en los datos de entrada.
Obtuvimos estas conclusiones sin aplicar el aprendizaje automático, y servirán como punto de partida para nuestros modelos posteriores.
Antes de entrenar modelos complejos, se recomienda manipular un poco los datos, hacer algunos gráficos y verificar suposiciones simples. Además, en las aplicaciones comerciales de aprendizaje automático, generalmente comienzan con soluciones simples y luego experimentan con soluciones más complejas.
Written by Tutor
Related View More
Clasificación de Texto con Python
Procesamiento y Transformación de Datos en Python
Análisis exploratorio en Python con Pandas
Bibliotecas para hacer análisis de datos en Python
Estructuras de Datos, Iteraciones y Condicionales en Python
Análisis de Datos con Python – Una Introducción
Estructura y Etiquetas en HTML5
Conceptos básicos de desarrollo web