Pasos para entrenar una red neuronal profunda

En esta implementación de Deep Learning, nuestro objetivo es predecir el desgaste de los clientes o la rotación de un determinado banco, y es probable que los clientes abandonen este servicio bancario. El conjunto de datos utilizado es relativamente pequeño y contiene 10000 filas con 14 columnas. Puedes descargarlo aquí.
Estamos utilizando la distribución de Anaconda y marcos como Theano, TensorFlow y Keras. Keras está construido sobre Tensorflow y Theano que funcionan como backends.
# Artificial Neural Network # Installing Theano pip install --upgrade theano # Installing Tensorflow pip install –upgrade tensorflow # Installing Keras pip install --upgrade keras
Paso 1
Preprocesamiento de datos
In[]:
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the database
dataset = pd.read_csv('Churn_Modelling.txt')
Paso 2
Creamos matrices de las características del conjunto de datos y la variable de destino, que es la columna 14, etiquetada como “Salido”.
El aspecto inicial de los datos se muestra a continuación:
In[]:
X = dataset.iloc[:, 3:13].values
Y = dataset.iloc[:, 13].values
Paso 3
Hacemos el análisis más simple codificando variables de cadena. Estamos utilizando la función ScikitLearn ‘LabelEncoder’ para codificar automáticamente las diferentes etiquetas en las columnas con valores entre 0 y n_classes-1.
from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X_1 = LabelEncoder() X[:,1] = labelencoder_X_1.fit_transform(X[:,1]) labelencoder_X_2 = LabelEncoder() X[:, 2] = labelencoder_X_2.fit_transform(X[:, 2])
Paso 4
Etiquetado de datos codificados
Usamos la misma biblioteca ScikitLearn y otra función llamada OneHotEncoder para simplemente pasar el número de columna creando una variable ficticia.
onehotencoder = OneHotEncoder(categorical features = [1]) X = onehotencoder.fit_transform(X).toarray() X = X[:, 1:]
Ahora, las dos primeras columnas representan el país y la cuarta columna representa el género.
Siempre dividimos nuestros datos en parte de entrenamiento y pruebas; capacitamos a nuestro modelo en los datos de entrenamiento y luego verificamos la precisión de un modelo en los datos de prueba que ayudan a evaluar la eficiencia del modelo.
Paso 5
Estamos utilizando la función train_test_split de ScikitLearn para dividir nuestros datos en el conjunto de entrenamiento y el conjunto de prueba. Mantenemos la relación de división de tren a prueba en 80:20.
#Splitting the dataset into the Training set and the Test Set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
Algunas variables tienen valores en miles, mientras que otras tienen valores en decenas o en unidades. Escalamos los datos para que sean más representativos.
Paso 6
En este código, estamos ajustando y transformando los datos de entrenamiento utilizando la función StandardScaler. Normalizamos nuestra escala de modo que utilicemos el mismo método ajustado para transformar / escalar datos de prueba.
# Feature Scaling fromsklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test)
Los datos ahora se escalan correctamente. Finalmente, hemos terminado con nuestro preprocesamiento de datos. Ahora, vamos a empezar con nuestro modelo.
Paso 7
Importamos los módulos requeridos aquí. Necesitamos el módulo secuencial para inicializar la red neuronal y el módulo denso para agregar las capas ocultas.
# Importing the Keras libraries and packages import keras from keras.models import Sequential from keras.layers import Dense
Paso 8
Nombraremos el modelo como Clasificador, ya que nuestro objetivo es clasificar la rotación de clientes. Luego usamos el módulo secuencial para la inicialización.
#Initializing Neural Network classifier = Sequential()
Paso 9
Añadimos las capas ocultas una a una usando la función densa. En el código de abajo, veremos muchos argumentos.
Nuestro primer parámetro es output_dim. Es el número de nodos que agregamos a esta capa. init es la inicialización del gradiente estocástico. En una red neuronal asignamos ponderaciones a cada nodo. En la inicialización, los pesos deben estar cerca de cero e inicializamos los pesos aleatoriamente usando la función uniforme. El parámetro input_dim es necesario solo para la primera capa, ya que el modelo no conoce el número de nuestras variables de entrada.
Aquí, el número total de variables de entrada es 11. En la segunda capa, el modelo conoce automáticamente el número de variables de entrada de la primera capa oculta.
Ejecute la siguiente línea de código para agregar la capa de entrada y la primera capa oculta:
classifier.add(Dense(units = 6, kernel_initializer = 'uniform', activation = 'relu', input_dim = 11))
Ejecute la siguiente línea de código para agregar la segunda capa oculta:
classifier.add(Dense(units = 6, kernel_initializer = 'uniform', activation = 'relu'))
Ejecute la siguiente línea de código para agregar la capa de salida:
classifier.add(Dense(units = 1, kernel_initializer = 'uniform', activation = 'sigmoid'))
Paso 10
Compilando la ANN
Hemos añadido varias capas a nuestro clasificador hasta ahora. Ahora los compilaremos usando el método de compilación. Los argumentos agregados en el control de compilación final completan la red neuronal. Por lo tanto, debemos tener cuidado en este paso.
Aquí hay una breve explicación de los argumentos.
El primer argumento es Optimizer. Este es un algoritmo utilizado para encontrar el conjunto óptimo de ponderaciones. Este algoritmo se llama el Descenso Estocástico de Gradiente (SGD). Aquí estamos usando uno entre varios tipos, llamado “optimizador de Adam”. El SGD depende de la pérdida, por lo que nuestro segundo parámetro es la pérdida. Si nuestra variable dependiente es binaria, usamos la función de pérdida logarítmica llamada “binary_crossentropy”, y si nuestra variable dependiente tiene más de dos categorías en la salida, entonces usamos “categorical_crossentropy”. Queremos mejorar el rendimiento de nuestra red neuronal en función de la precisión, por lo que agregamos métricas como precisión.
# Compiling Neural Network classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
Paso 11
Se deben ejecutar varios códigos en este paso.
Ajuste de la ANN al conjunto de entrenamiento
Ahora entrenamos nuestro modelo en los datos de entrenamiento. Utilizamos el método de ajuste para ajustar nuestro modelo. También optimizamos los pesos para mejorar la eficiencia del modelo. Para ello, tenemos que actualizar los pesos. El tamaño del lote es el número de observaciones después de lo cual actualizamos los pesos. Época es el número total de iteraciones. Los valores de tamaño de lote y época se eligen mediante el método de prueba y error.
classifier.fit(X_train, y_train, batch_size = 10, epochs = 50)
Haciendo predicciones y evaluando el modelo.
# Predicting the Test set results y_pred = classifier.predict(X_test) y_pred = (y_pred > 0.5)
Predecir una sola observación nueva
# Predicting a single new observation """Our goal is to predict if the customer with the following data will leave the bank: Geography: Spain Credit Score: 500 Gender: Female Age: 40 Tenure: 3 Balance: 50000 Number of Products: 2 Has Credit Card: Yes Is Active Member: Yes
Paso 12
Predecir el resultado del conjunto de pruebas
El resultado de la predicción le dará la probabilidad de que el cliente abandone la empresa. Convertiremos esa probabilidad en binario 0 y 1.
# Predicting the Test set results y_pred = classifier.predict(X_test) y_pred = (y_pred > 0.5) new_prediction = classifier.predict(sc.transform (np.array([[0.0, 0, 500, 1, 40, 3, 50000, 2, 1, 1, 40000]]))) new_prediction = (new_prediction > 0.5)
Paso 13
Este es el último paso donde evaluamos el rendimiento de nuestro modelo. Ya tenemos resultados originales y, por lo tanto, podemos crear una matriz de confusión para verificar la precisión de nuestro modelo.
Haciendo la Matriz de Confusión
from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred) print (cm) Output loss: 0.3384 acc: 0.8605 [ [1541 54] [230 175] ]
Desde la matriz de confusión, la precisión de nuestro modelo se puede calcular como:
Accuracy = 1541+175/2000=0.858
Logramos un 85.8% de precisión, lo cual es bueno.
El algoritmo de propagación hacia adelante
En esta sección, aprenderemos cómo escribir código para hacer una propagación (predicción) hacia adelante para una red neuronal simple:
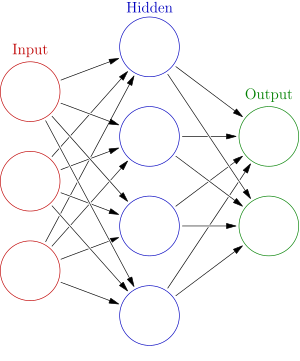
Cada punto de datos es un cliente. La primera entrada es cuántas cuentas tienen, y la segunda es cuántos hijos tienen. El modelo predecirá cuántas transacciones realizará el usuario en el próximo año.
Los datos de entrada se cargan previamente como datos de entrada, y los pesos están en un diccionario llamado pesos. La matriz de pesos para el primer nodo en la capa oculta está en pesos [‘node_0’], y para el segundo nodo en la capa oculta están en pesos [‘node_1’] respectivamente.
Los pesos que se alimentan en el nodo de salida están disponibles en pesos.
La función de activación lineal rectificada
Una “función de activación” es una función que funciona en cada nodo. Transforma la entrada del nodo en alguna salida.
La función de activación lineal rectificada (llamada ReLU) se usa ampliamente en redes de muy alto rendimiento. Esta función toma un solo número como entrada, devolviendo 0 si la entrada es negativa, e ingresa como salida si la entrada es positiva.
Aquí hay algunos ejemplos:
relu (4) = 4
relu (-2) = 0
Completamos la definición de la función relu () –
Usamos la función max () para calcular el valor de la salida de relu ().
Aplicamos la función relu () a node_0_input para calcular node_0_output.
Aplicamos la función relu () a node_1_input para calcular node_1_output.
import numpy as np
input_data = np.array([-1, 2])
weights = {
'node_0': np.array([3, 3]),
'node_1': np.array([1, 5]),
'output': np.array([2, -1])
}
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = np.tanh(node_0_input)
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = np.tanh(node_1_input)
hidden_layer_output = np.array(node_0_output, node_1_output)
output =(hidden_layer_output * weights['output']).sum()
print(output)
def relu(input):
'''Define your relu activation function here'''
# Calculate the value for the output of the relu function: output
output = max(input,0)
# Return the value just calculated
return(output)
# Calculate node 0 value: node_0_output
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value: node_1_output
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output (do not apply relu)
odel_output = (hidden_layer_outputs * weights['output']).sum()
print(model_output)# Print model output
Output
0.9950547536867305
-3
Aplicando la red a muchas observaciones / filas de datos.
En esta sección, aprenderemos cómo definir una función llamada predict_with_network (). Esta función generará predicciones para múltiples observaciones de datos, tomadas de la red anterior, tomadas como input_data. Se están utilizando los pesos dados en la red anterior. La definición de la función relu () también se está utilizando.
Definamos una función llamada predict_with_network () que acepta dos argumentos, input_data_row y pesos, y devuelve una predicción de la red como salida.
Calculamos los valores de entrada y salida para cada nodo, almacenándolos como: node_0_input, node_0_output, node_1_input, y node_1_output.
Para calcular el valor de entrada de un nodo, multiplicamos las matrices relevantes y calculamos su suma.
Para calcular el valor de salida de un nodo, aplicamos la función relu () al valor de entrada del nodo. Utilizamos un ‘for loop’ para iterar sobre input_data –
También utilizamos nuestro predict_with_network () para generar predicciones para cada fila de input_data – input_data_row. También anexamos cada predicción a los resultados.
# Define predict_with_network() def predict_with_network(input_data_row, weights): # Calculate node 0 value node_0_input = (input_data_row * weights['node_0']).sum() node_0_output = relu(node_0_input) # Calculate node 1 value node_1_input = (input_data_row * weights['node_1']).sum() node_1_output = relu(node_1_input) # Put node values into array: hidden_layer_outputs hidden_layer_outputs = np.array([node_0_output, node_1_output]) # Calculate model output input_to_final_layer = (hidden_layer_outputs*weights['output']).sum() model_output = relu(input_to_final_layer) # Return model output return(model_output) # Create empty list to store prediction results results = [] for input_data_row in input_data: # Append prediction to results results.append(predict_with_network(input_data_row, weights)) print(results)# Print results Output [0, 12]
Aquí hemos usado la función relu donde relu (26) = 26 y relu (-13) = 0 y así sucesivamente.
Redes neuronales multicapa profundas
Aquí estamos escribiendo código para hacer una propagación hacia adelante para una red neuronal con dos capas ocultas. Cada capa oculta tiene dos nodos. Los datos de entrada se han cargado previamente como input_data. Los nodos en la primera capa oculta se llaman node_0_0 y node_0_1.
Sus pesos se cargan previamente como weights[‘node_0_0’] y weights[‘node_0_1’] respectivamente.
Los nodos en la segunda capa oculta se llaman node_1_0 y node_1_1. Sus pesos se cargan previamente como weights[‘node_1_0’] y weights[‘node_1_1’] respectivamente.
Luego creamos una salida de modelo a partir de los nodos ocultos usando ponderaciones precargadas como weights[‘output’].
Calculamos node_0_0_input utilizando sus ponderaciones weights[‘node_0_0’] y los datos de entrada especificados. Luego aplique la función relu() para obtener node_0_0_output.
Hacemos lo mismo que anteriormente para node_0_1_input para obtener node_0_1_output.
Calculamos node_1_0_input utilizando sus ponderaciones weights[‘node_1_0’] y los resultados de la primera capa oculta: hidden_0_outputs. Luego aplicamos la función relu() para obtener node_1_0_output.
Hacemos lo mismo que anteriormente para node_1_1_input para obtener node_1_1_output.
Calculamos model_output utilizando weights[‘output’] y las salidas de la segunda capa oculta en la matriz hidden_1_outputs. No aplicamos la función relu() a esta salida.
import numpy as np
input_data = np.array([3, 5])
weights = {
'node_0_0': np.array([2, 4]),
'node_0_1': np.array([4, -5]),
'node_1_0': np.array([-1, 1]),
'node_1_1': np.array([2, 2]),
'output': np.array([2, 7])
}
def predict_with_network(input_data):
# Calculate node 0 in the first hidden layer
node_0_0_input = (input_data * weights['node_0_0']).sum()
node_0_0_output = relu(node_0_0_input)
# Calculate node 1 in the first hidden layer
node_0_1_input = (input_data*weights['node_0_1']).sum()
node_0_1_output = relu(node_0_1_input)
# Put node values into array: hidden_0_outputs
hidden_0_outputs = np.array([node_0_0_output, node_0_1_output])
# Calculate node 0 in the second hidden layer
node_1_0_input = (hidden_0_outputs*weights['node_1_0']).sum()
node_1_0_output = relu(node_1_0_input)
# Calculate node 1 in the second hidden layer
node_1_1_input = (hidden_0_outputs*weights['node_1_1']).sum()
node_1_1_output = relu(node_1_1_input)
# Put node values into array: hidden_1_outputs
hidden_1_outputs = np.array([node_1_0_output, node_1_1_output])
# Calculate model output: model_output
model_output = (hidden_1_outputs*weights['output']).sum()
# Return model_output
return(model_output)
output = predict_with_network(input_data)
print(output)
Output
364
Written by Tutor
Related View More
Redes neuronales profundas – Tipos y Características
Aprendizaje profundo y el aprendizaje de máquina tradicional
Requerimientos para Aprendizaje Profundo en Python
Estructura y Etiquetas en HTML5
Conceptos básicos de desarrollo web
Hadoop Explicado
Procesamiento Básico de Datos con Python
Los modelos de datos en una base de datos