Análisis estadístico con Python y statsmodels
 Tutor | octubre 28, 2018
Tutor | octubre 28, 2018
Esta clase proporciona funciones para la estimación de muchos modelos estadísticos diferentes, así como para realizar pruebas estadísticas y exploración de datos estadísticos con el uso de la biblioteca statsmodels.
Conocimientos en programación en python y estadística son necesarios.
Este caso de estudio muy simple está diseñado para que puedas ponerte en funcionamiento rápidamente con statsmodels. A partir de datos sin procesar, mostraremos los pasos necesarios para estimar un modelo estadístico y dibujar un gráfico para evaluar los resultados.
Cargando módulos y funciones
Después de instalar statsmodels y sus dependencias, cargamos algunos módulos y funciones:
from __future__ import print_function import statsmodels.api as sm import pandas from patsy import dmatrices
pandas se basa en listas para proporcionar estructuras de datos enriquecidas y herramientas de análisis de datos. La función pandas.DataFrame proporciona matrices etiquetadas de datos.
La función pandas.read_csv se puede usar para convertir un archivo de valores separados por comas en un objeto DataFrame.
patsy es una biblioteca de Python para describir modelos estadísticos y construir matrices de diseño utilizando fórmulas tipo R.
Datos
Descargamos el conjunto de datos de Guerry, una recopilación de datos históricos utilizados en apoyo del Ensayo sobre las estadísticas morales de Francia de 1833 de Andre-Michel Guerry. El conjunto de datos se hospeda en línea en el formato de valores separados por comas (CSV) del repositorio de Rdatasets.
Podríamos descargar el archivo localmente y luego cargarlo usando read_csv, pero pandas se encarga de todo esto automáticamente por nosotros:
df = sm.datasets.get_rdataset("Guerry", "HistData").data
Seleccionamos las variables de interés y miramos las 5 últimas filas:
vars = ['Department', 'Lottery', 'Literacy', 'Wealth', 'Region'] df = df[vars] df[-5:]
Resultado
Department Lottery Literacy Wealth Region 81 Vienne 40 25 68 W 82 Haute-Vienne 55 13 67 C 83 Vosges 14 62 82 E 84 Yonne 51 47 30 C 85 Corse 83 49 37 NaN
Observe que falta una observación en la columna Region. Lo eliminamos utilizando un método DataFrame provisto por pandas:
df = df.dropna() df[-5:]
Resultado
Department Lottery Literacy Wealth Region 80 Vendee 68 28 56 W 81 Vienne 40 25 68 W 82 Haute-Vienne 55 13 67 C 83 Vosges 14 62 82 E 84 Yonne 51 47 30 C
Problema y Modelo
Queremos saber si las tasas de alfabetización en los 86 departamentos franceses están asociadas con las apuestas en la Lotería Real en la década de 1820. Necesitamos ver el nivel de riqueza en cada departamento, y también queremos incluir una serie de variables ficticias en el lado derecho de nuestra ecuación de regresión para controlar la heterogeneidad no observada debido a los efectos regionales.
El modelo se estima utilizando la regresión de mínimos cuadrados ordinarios o MCO (OLS en inglés).
Matrices de diseño
Para ajustar la mayoría de los modelos cubiertos por statsmodels, deberá crear dos matrices de diseño. La primera es una matriz de variables endógena (es decir, dependiente, respuesta, regresión y etc.). El segundo es una matriz de variables exógena (es decir, independiente, predictor, regresor, etc.).
El módulo patsy proporciona una función conveniente para preparar matrices de diseño utilizando fórmulas tipo R.
Usamos la función dmatrices de patsy para crear matrices de diseño:
y, X = dmatrices('Lottery ~ Literacy + Wealth + Region', data=df, return_type='dataframe')
y[:3]
Resultado
Lottery 0 41.0 1 38.0 2 66.0 Intercept Region[T.E] Region[T.N] Region[T.S] Region[T.W] Literacy \ 0 1.0 1.0 0.0 0.0 0.0 37.0 1 1.0 0.0 1.0 0.0 0.0 51.0 2 1.0 0.0 0.0 0.0 0.0 13.0 Wealth 0 73.0 1 22.0 2 61.0
Ajustar el modelo y resumir
El ajuste de un modelo en statsmodels generalmente implica 3 pasos sencillos:
- Usa la clase modelo para describir el modelo
- Ajustar el modelo utilizando un método de clase.
- Inspeccionar los resultados utilizando un método de resumen.
Para regresión de mínimos cuadrados ordinarios, esto se logra mediante:
mod = sm.OLS(y, X) # Describe el modelo res = mod.fit() # Ajusta el modelo print(res.summary()) # Resume el modelo
Resultado
OLS Regression Results
==============================================================================
Dep. Variable: Lottery R-squared: 0.338
Model: OLS Adj. R-squared: 0.287
Method: Least Squares F-statistic: 6.636
Date: Mon, 14 May 2018 Prob (F-statistic): 1.07e-05
Time: 21:48:07 Log-Likelihood: -375.30
No. Observations: 85 AIC: 764.6
Df Residuals: 78 BIC: 781.7
Df Model: 6
Covariance Type: nonrobust
===============================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------
Intercept 38.6517 9.456 4.087 0.000 19.826 57.478
Region[T.E] -15.4278 9.727 -1.586 0.117 -34.793 3.938
Region[T.N] -10.0170 9.260 -1.082 0.283 -28.453 8.419
Region[T.S] -4.5483 7.279 -0.625 0.534 -19.039 9.943
Region[T.W] -10.0913 7.196 -1.402 0.165 -24.418 4.235
Literacy -0.1858 0.210 -0.886 0.378 -0.603 0.232
Wealth 0.4515 0.103 4.390 0.000 0.247 0.656
==============================================================================
Omnibus: 3.049 Durbin-Watson: 1.785
Prob(Omnibus): 0.218 Jarque-Bera (JB): 2.694
Skew: -0.340 Prob(JB): 0.260
Kurtosis: 2.454 Cond. No. 371.
==============================================================================
El objeto res tiene muchos atributos útiles. Por ejemplo, podemos extraer estimaciones de parámetros y r-cuadrado escribiendo:
res.params
Escriba dir(res) para obtener una lista completa de atributos.
Diagnósticos y Tests
También puedes realizar una variedad de diagnósticos de regresión útiles y tests. Por ejemplo, aplica la prueba Rainbow para la linealidad (la hipótesis nula es que la relación se modela correctamente como lineal):
sm.stats.linear_rainbow(res)
Resultado
(0.8472339976156913, 0.6997965543621643)
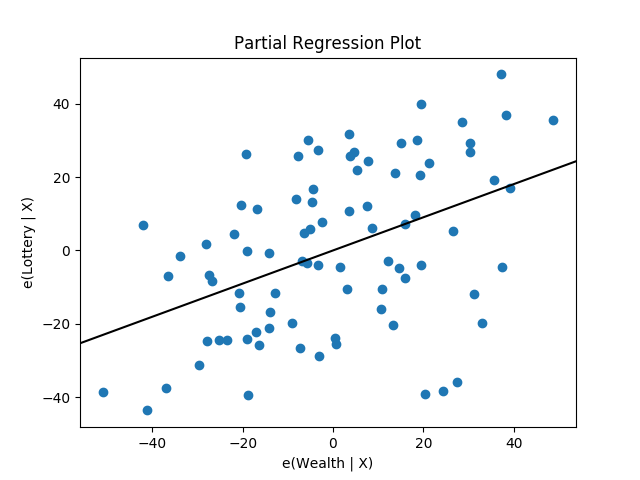
statsmodels también proporciona funciones gráficas. Por ejemplo, podemos dibujar una gráfica de regresión parcial para un conjunto de regresores por:
sm.graphics.plot_partregress('Lottery', 'Wealth', ['Region', 'Literacy'],
data=df, obs_labels=False)
Para más información mira el curso completo de Estadística para Python.
Written by Tutor
Related View More
Tutor | octubre 28, 2018
Funciones Básicas de Estadística
Tutor | octubre 28, 2018
Modelos lineales generalizados con Python y statsmodels
Tutor | octubre 28, 2018
Regresión lineal con Python y statsmodels
Tutor | marzo 11, 2022
Estructura y Etiquetas en HTML5
Tutor | marzo 11, 2022
Conceptos básicos de desarrollo web
Tutor | marzo 9, 2022
Hadoop Explicado
Tutor | marzo 7, 2022
Procesamiento Básico de Datos con Python
Tutor | diciembre 19, 2021
Los modelos de datos en una base de datos
Tutor | marzo 3, 2020